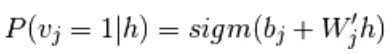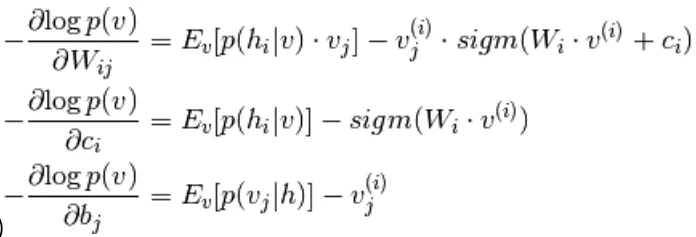En apprentissage automatique, la machine de Boltzmann restreinte (en anglais : restricted boltzmann machine ou RBM) est un type de réseau de neurones artificiels pour l'apprentissage non supervisé.
Une RBM est constituée de deux couches de neurones : une couche visible représentant les variables d'entrée et une couche cachée représentant les variables latentes apprises par le modèle. Les neurones visibles sont connectés aux neurones cachés, sans connexion au sein de chaque couche. Fondés sur des modèles de probabilité, les états des neurones sont déterminés par des probabilités conditionnelles. L'apprentissage se fait par l'algorithme de contrastive divergence (CD), qui ajuste les poids et biais pour minimiser la divergence entre les distributions des données d'entrée et celles générées par le modèle.
La machine de Boltzmann restreinte est couramment utilisée pour estimer la distribution probabiliste d'un jeu de données. Elle a initialement été inventée sous le nom de Harmonium en 1986 par Paul Smolenski. Elle entre dans le cadre des modèles graphiques et des modèles à base d'énergie.
Description
La machine de Boltzmann restreinte est en fait un cas particulier de machine de Boltzmann où les neurones d'une même couche sont indépendants entre eux.
Machine de Boltzmann
Dans sa forme la plus simple, une machine de Boltzmann est composée d'une couche de neurones qui reçoit l'entrée, ainsi que d'une couche de neurones cachée.
On définit l'énergie pour une configuration de donnée de la manière suivante :
où :
- est le poids entre le neurone et le neurone ;
- est l'état, , du neurone visible ;
- est l'état du neurone caché ;
- et sont respectivement les biais des neurones et .
La probabilité conjointe d'avoir une configuration est alors donnée par :
avec :
- la fonction d'énergie définie ci-dessus ;
- une constante de normalisation, qui fait en sorte que la somme de toutes les probabilités fasse 1.
Apprentissage
La machine de Boltzmann s’entraîne à l'aide d'un apprentissage non supervisé. On cherche à minimiser la log-vraisemblance. La dérivée de la log-vraisemblance donne l'expression suivante :
avec :
- les variables du système (les poids ou le biais) ;
- l'espérance mathématique sur les variables aléatoires et ;
- une valeur du jeu de données ;
- l'énergie définie ci-dessus.
On remarque la présence de deux termes dans cette expression, appelés phase positive et phase négative. La phase positive se calcule aisément pour le biais et pour la matrice des poids.
On obtient alors :
avec h(x) l'état de la couche cachée sachant x donnée par la formule
.
La partie la plus compliquée est de calculer ce qu'on appelle la phase négative. On ne peut pas la calculer directement car on ne connaît pas la constante de normalisation du système. Pour pouvoir effectuer une descente de gradient, on calcule ce que l'on appelle la reconstruction de l'entrée . En effet, les propriétés de symétrie du système permettent de calculer l'entrée estimée par le modèle, il suffit d'appliquer la formule :
avec le biais de la couche cachée de neurones .
De la même manière, on peut recalculer l'état de la couche cachée en réitérant le procédé. Finalement, on peut résumer l'algorithme de descente du gradient ainsi (on parle de l'algorithme de contrastive divergence, couramment abrégé CD-k) :
Notes et références
Voir aussi
Articles connexes
- Champ aléatoire de Markov
- Modèle d'Ising
- Réseau de neurones de Hopfield
- Portail des neurosciences
- Portail des probabilités et de la statistique
- Portail des données
- Portail de l'informatique théorique